


日前,KDD2021论文录取结果出炉,今年共有1541篇有效投稿,其中238篇论文被接收,接收率为15.44%,相比KDD2020的接收率16.9%有所下降。深兰科技的论文《AutoSmart: An Efficient and Automatic Machine Learning framework for Temporal Relational Data》,通过全自动特征工程、多表合并、模型调整和资源控制,用AutoSmart框架为时序相关的表数据提供了高效的自动机器学习解决方案,并被KDD2021录用。

此前,深兰科技还多次在国际顶级学术期刊/会议上发表论文,包括以自适应的集成学习方法为主要内容的《Winning solutions and post-challenge analyses of the ChaLearn AutoDL challenge 2019》被计算机视觉及模式识别领域的顶级期刊TPAMI 2021收录,以空气质量预测为主题的论文《AccuAir: Winning Solution to Air Quality Prediction for KDD Cup 2018》被KDD 2019 ADS track录取为Oral Paper等。

关于KDD
ACM SIGKDD(国际数据挖掘与知识发现大会,简称 KDD)是世界数据挖掘领域的最高级别的学术会议,由 ACM 的数据挖掘及知识发现专委会(SIGKDD)主办,被中国计算机协会推荐为 A 类会议。自 1995 年以来,KDD 已经连续举办了26届,今年将于2021年8月14日至18日在新加坡举办。
论 文 解 读

概述
时序相关的表数据,是工业机器学习应用程序中最常用的数据类型之一,需要劳动密集型的特征工程和数据分析才能提供精确的模型预测。因此,自动机器学习框架可以大大减少手动调优的工作量,以便专家可以将更多精力放在真正需要人类参与的其他问题上,例如问题定义,部署和业务服务。但是,建立时序相关表数据的自动机器学习框架存在三个主要挑战:如何有效、自动地从多个表中挖掘有用的信息以及它们之间的关系;如何使框架自我调整,并在一定预算内控制时间和内存消耗;如何为各种任务提供通用解决方案。
在这项工作中,深兰科技提出了一种解决方案,以端到端的自动方式成功解决了上述问题。论文中提出的框架AutoSmart基于深兰科技在KDD Cup 2019中AutoML Track冠军方案,这是迄今为止最大的AutoML竞赛之一((860支团队,约4,955份参赛作品)。该框架包括自动数据处理、表合并、特征工程和模型调整,并带有时间和内存控制器,可高效、自动地制定模型。论文所提出的框架在各个领域的多个数据集上均明显优于基准解决方案。

实验结果
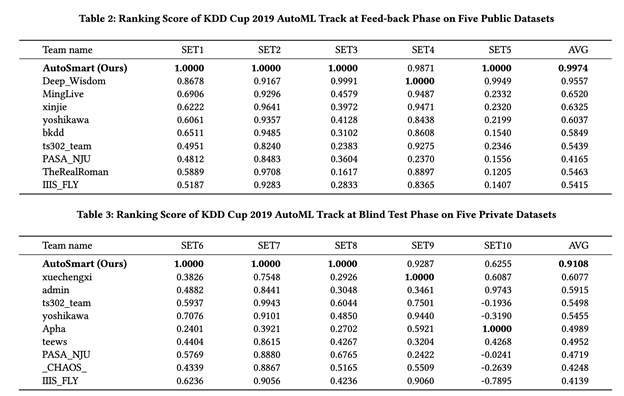
上面两张表展示了方案在五个公开数据集和五个未公开数据集的结果,这五个数据集涉及不同的领域。
可以看到:
在五个公开数据集上,深兰团队工作的平均得分比第二名高出4.14%,而在五个未公布数据集上,这一数字增加到30.31%;
大多数团队的结果显示不同数据集上的性能不稳定;
在五个公开数据集上表现良好的一些排名靠前的团队(例如Deep_Wisdom和MingLive),无法在五个未公布数据集上获得相似的性能。
所有这些发现都充分证明了论文中提出的,针对时态关系数据的AutoML框架的有效性和鲁棒性,其在所有数据集上均表现出良好且稳定的性能。

模型细节
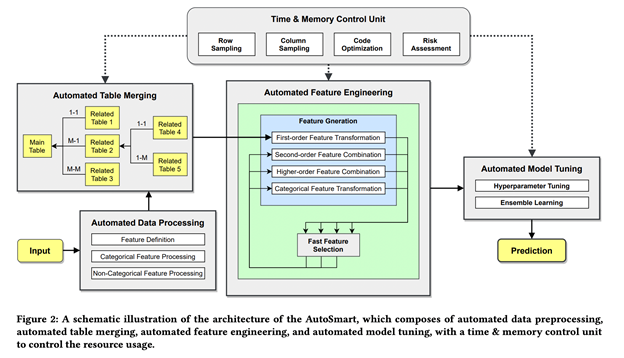
论文提出的框架由四个自动模块组成,包括:
数据预处理;
表合并;
特征工程;
模型调整;
用于控制模型时间和内存使用的时间记忆控制器。
整个框架结构由下图所示。
3.1 问题定义
时间关系数据通常代表多个关系表,即一个描述有关键ID的时间信息的主表,以及几个包含有关键ID的辅助信息的相关表,其中Key IDs是主表之间的连接列以及相关表格。
时间关系表的示例在下图中显示,其中Key ID这里是User ID和Item ID。

3.2 技术创新
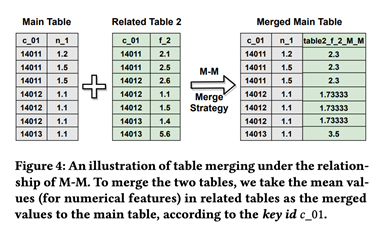
下图描述了多表融合最复杂情况多对多(M-M)情况的处理:表A中的一行可能与表B中的许多行链接在一起,反之亦然。深兰团队根据特征类型(即分类或多分类特征,数字特征或时间特征)合并相关表。例如,对于数字特征和分类特征,团队将相关表中的平均值和众数作为主表中key ids的值。至于时间特征,则将最新时间作为主表的合并值。
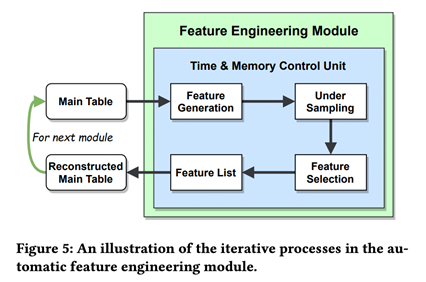
为了充分利用表信息并最大程度地减少内存使用量,我们将特征工程划分为四个顺序的模块。对于每个模块,我们使用LightGBM来验证每个特征的有效性并进行功能选择。此处特征工程是通过多个模块递归进行的,在每个模块的开头,都会从主表中生成新功能,然后根据向下采样的子数据集进行功能选择,再从中使用所选功能来更新主表。
LightGBM模型的两个主要超参数是boosting轮数和学习率,其他大多数团队都使用贝叶斯优化进行超参数调整。但是,这种方法需要对整个样本进行多次训练才能获得超参数的性能分布,这在时间上效率低下,尤其是在处理大规模数据集时。不同的是,深兰团队利用先验知识来实现类似包装器的方法,以减少搜索空间。借助采样数据或小规模的boosting回合,即使没有一次完整的模型训练也能快速获得成功的必要先验知识,从而得到预设的学习率和boosting轮数。
3.3 资源控制
模型学习花费了大部分培训时间,在框架中利用集成学习的力量来构建模型。相应地,在给定时间预算的情况下,模型可以自动快速地适应最佳情况。
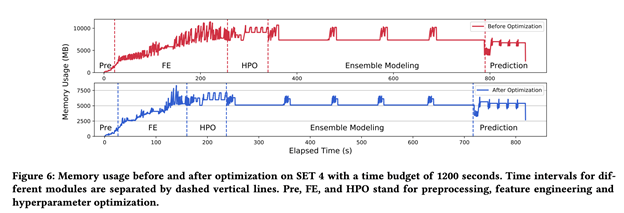
下图给出了内存控制之前和之后的模型性能示例。可以看到,特征工程中的优化减少了处理时间。通过节省时间,可以将一个新模型自动添加到集成建模中,以获得更好的结果。

总结
在这项工作中,深兰团队为时态关系数据提出了一个高效且自动的机器学习框架AutoSmart,包括自动数据处理、表合并、功能工程和模型调整,并与时间和内存控制单元集成在一起。
实验表明,AutoSmart
可以有效地挖掘有用的信息,并在不同的时间关系数据集上提供一致的出色性能;
可以在时间和内存预算内有效地对给定的数据集进行自我调整;
可扩展到更大比例或某些极端情况(例如,缺失值太多)的数据集。
简而言之,论文中所提出的框架可以在不同情况下实现最佳和稳定的性能。此外,论文代码是公开的,并可以方便地应用于工业应用。
本文地址: https://www.xsyiq.com/1228.html
网站内容如侵犯了您的权益,请联系我们删除。
